
Data Pruning at Scale


Table of Contents
Motivation
Sample Quantity Reduction through Embedding Space Exploration
Data Quality Control through Better CLIP Scores
Conclusion and Future Works
Motivation
Deep learning models are often carefully tuned for performance and optimized for deployment, but what about datasets? For each part of the model development pipeline, data quality is often overlooked in research, impacting model outcomes. Top researchers manually inspect new datasets for biases and errors (e.g. ImageNet) to understand how model performance could be impacted in downstream tasks. This is vital in the era of 'world models,' where industry labs train large language models (LLMs) on the entirety of internet data. The key question is: how do we efficiently ensure data quality at scale?”
We start off this discussion by defining what high quality data means and why it is important.
“Garbage in, Garbage Out” ~ George Fueschel, 1957
The timeless quote by Fueschel translates to today’s world in explaining how models trained on bad data end up underperforming. This problem motivates the use of high quality data, which can be defined as sufficiently diverse and individually informative:
Diverse: training a model on a replicated or closely-replicated data point is redundant and can lead to overfitting, so it’s important to get rid of such duplicate data.
Informative: In a model training context, information can be explained as follows:
Task-relevance is a more intuitive concept for supervised (labeled) downstream tasks but can be abstracted in pretraining to whether including a certain data point could help improve a models performance on many diverse downstream tasks.
In a multimodal setting where data comes from heterogenous sources (e.g. images and text), there also exist interactions between data. In recent work shown in this paper and Twitter/X thread, the type and amount of multimodal interactions in data significantly influence modeling and training decisions.
Now that we’ve provided a basic definition, why is working on data quality and curation at scale such an important research question?
Similar to model evaluation, data pruning approaches can be divided into the two main categories of quantity vs quality. Dataset size can be quantitatively reduced through embedding space deduplication approaches in which modality-agnostic vectorized data embeddings generated by a pretrained model are analyzed and removed from the original dataset based on certain properties. Data is also filtered for quality by evaluating each sample via some model-based scoring mechanism.
To evaluate different approaches, there needs to be a standardized benchmark like the ImageNet competition but for data filtration. This is where DataComp comes in (and similar competitions like DataPerf). After curating internet-scale image-text pairs, providing some basic cleaning and filtration, and setting a baseline benchmark algorithm using CLIP scores, this competition evaluates data curation algorithms at scale to accelerate the development of better datasets. In the following sections, we’ll analyze some of the winning solutions and adjacent methods proposed for improved data curation.
Sample Quantity Reduction through Embedding Space Exploration
Much of this work, especially from FAIR, builds off from each other. We’ll go through the progression of data pruning developments by chaining each of these papers in approximate order.
SemDeDup: Data-Efficient Learning at Web-Scale through Semantic Deduplication
Paper: https://arxiv.org/abs/2303.09540
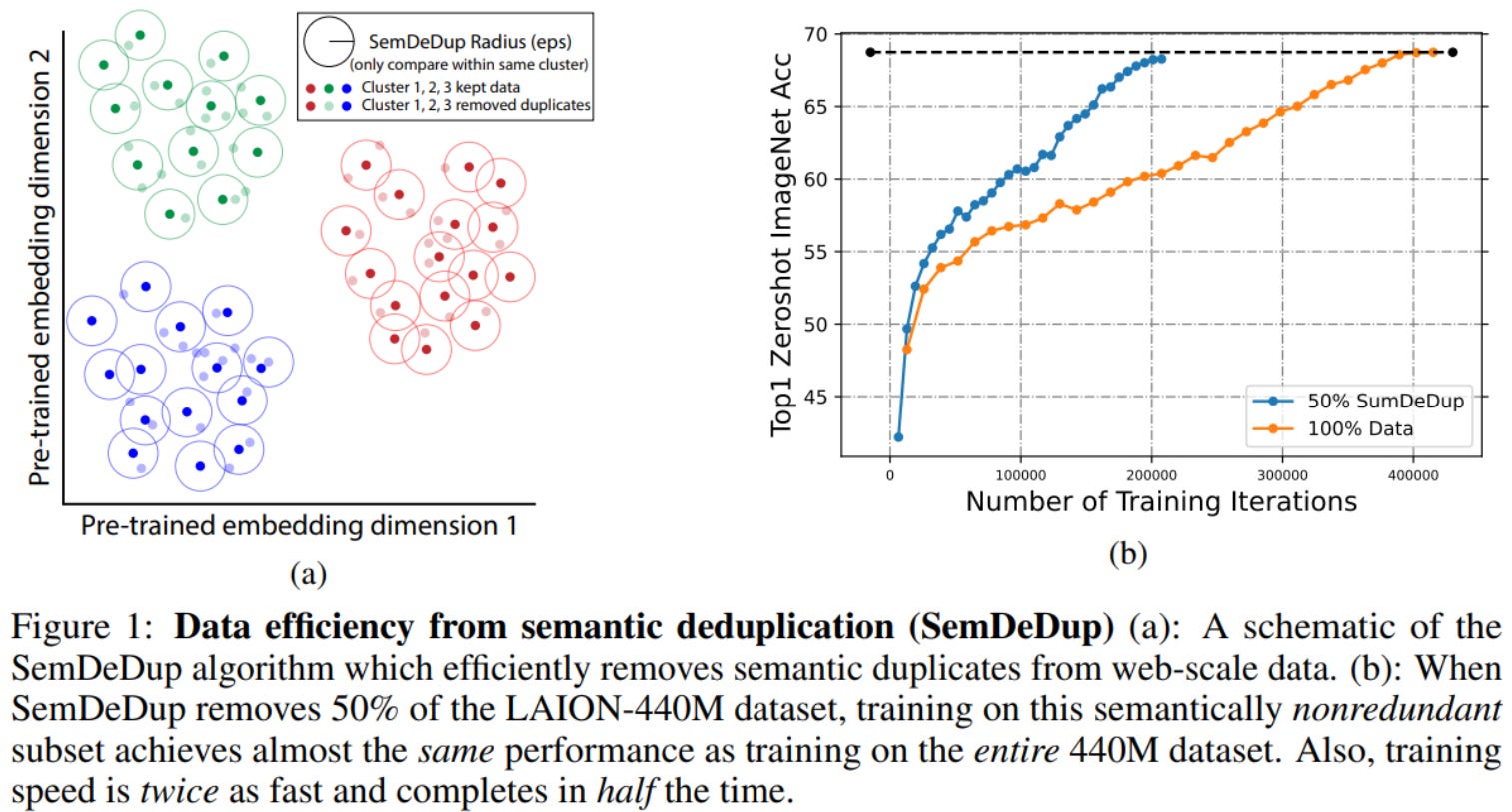
Since the power law scaling of training data is unsustainable and has diminishing marginal returns, there is a need to improve data quality rather than quantity. This motivation points towards removing “bad” redundant data, which can be divided into the following groups: perceptual duplicates (look the same), semantic duplicates (mean the same thing), semantically redundant data (very close representations), and misleading data (unaligned or irrelevant).
To get rid of semantically redundant duplicates, the SemDeDup algorithm efficiently does so at scale:
Use large pretrained foundation model to generate meaningful embeddings (e.g. CLIP/BLIP for image-text, OPT for language)
Use K-means clustering (heuristic for number of k clusters in paper)
Within each cluster, compute all pairwise cosine similarities and set a threshold cosine similarity score above which all data pairs that are considered semantically redundant
Within semantic duplicates for a cluster, keep the data sample associated with the embedding with the lowest cosine similarity and remove the rest
Concept-based Data-driven Curation of Large-Scale Datasets
DataComp Presentation, no paper yet
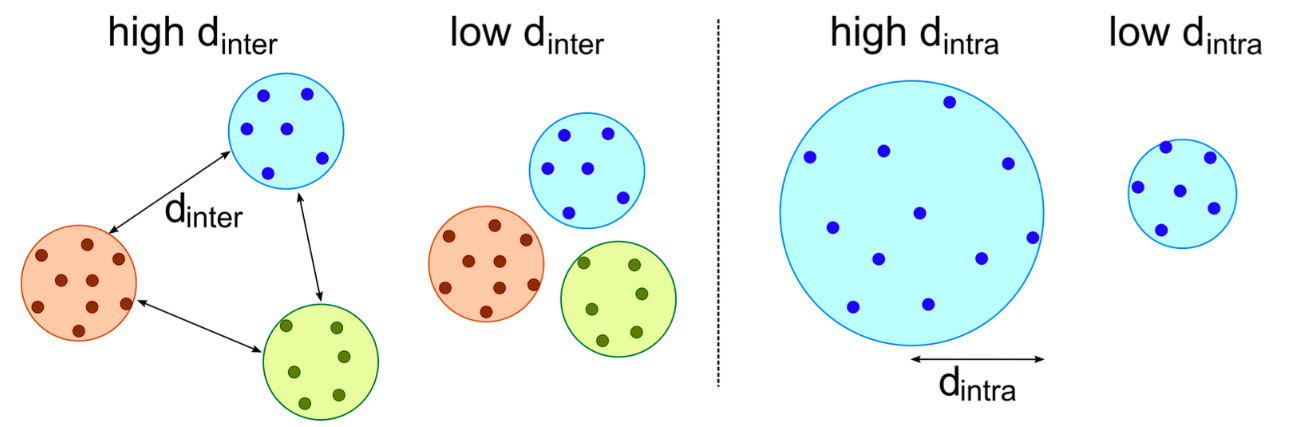
After perceptual deduplication and running the SemDeDup algorithm, the resulting latent space should now have a more sparse structure. The novelty of this method is what they call “Density-based Pruning”. Through empirical validation, they find that clusters that are more sparse have less redundancy and should thus be sampled from more, calculated as summing the distance between all samples in a cluster to the centroid and ranking total distances (d_{intra}). To optimize for diversity, they maximize distance between clusters (d_{inter}). The product of these two metrics is a score for each data sample, which are then softmax’d for normalization. Since there are two constraints, these metrics can be optimized by quadratic programming. Since this method doesn’t explicitly control for quality, they find that including CLIP-score filtering improves the results (more discussion in the data quality section).
Decoding Data Quality via Synthetic Corruptions: Embedding-Guided Pruning of Code Data
Paper: https://arxiv.org/abs/2312.02418
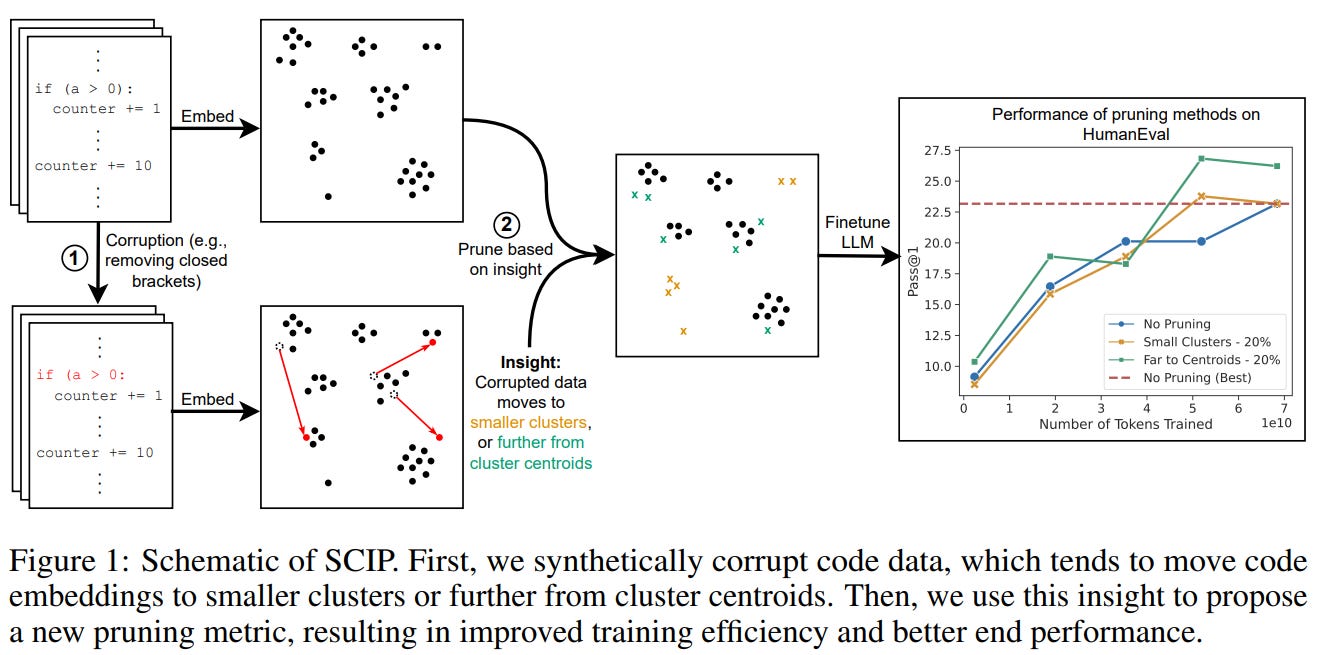
This is another embedding space pruning paper, but tackled from a data augmentation perspective. They use synthetic data that is created by artificially introducing errors into clean code to controllably understand how bugs and thus data quality can affect outputted embeddings. Examples of such synthetic corruptions are:
Syntax errors: removing closing brackets and renaming variables
Logical errors: negate conditional operators or offset array indices
This synthetically corrupted data is then embedded with a pretrained model along with internet-scale code data. The main insight was that corrupted code moves to smaller clusters and further from cluster centroids as they are considered outliers. Thus, a new metric was created to rank data points by cluster size and distance to nearest centroid.
I found the future work section particularly interesting:
Use heuristics to identify low-quality data via synthetic corruptions to see towards what spaces that these low quality embeddings drift towards
Natural language data can also have structural (e.g. grammatical) and semantic (e.g. factually incorrect) anomalies so you could theoretically leverage this framework to prune out low-quality data. (Haoli’s Thoughts:) Beyond text data, this framework could potentially apply to continuous real-valued data like images or other modalities by tracking data augmentations in latent space for interpretability-informed data pruning.
D4: Improving LLM Pretraining via Document De-Duplication and Diversification
Paper: https://arxiv.org/abs/2308.12284
In this paper, the authors embedded web-scale text documents, clustered embeddings with K-means, and manually inspected the resulting clusters to find that several high density clusters had documents generated from templates with minimal changes. This redundancy provides motivation for pruning.
D4 algorithm:
Apply SemDeDup method
Recluster sparsified embedding space with K-means again
Apply SSL prototypes method to prune out embeddings closest to centroids to enrich higher variance outliers.
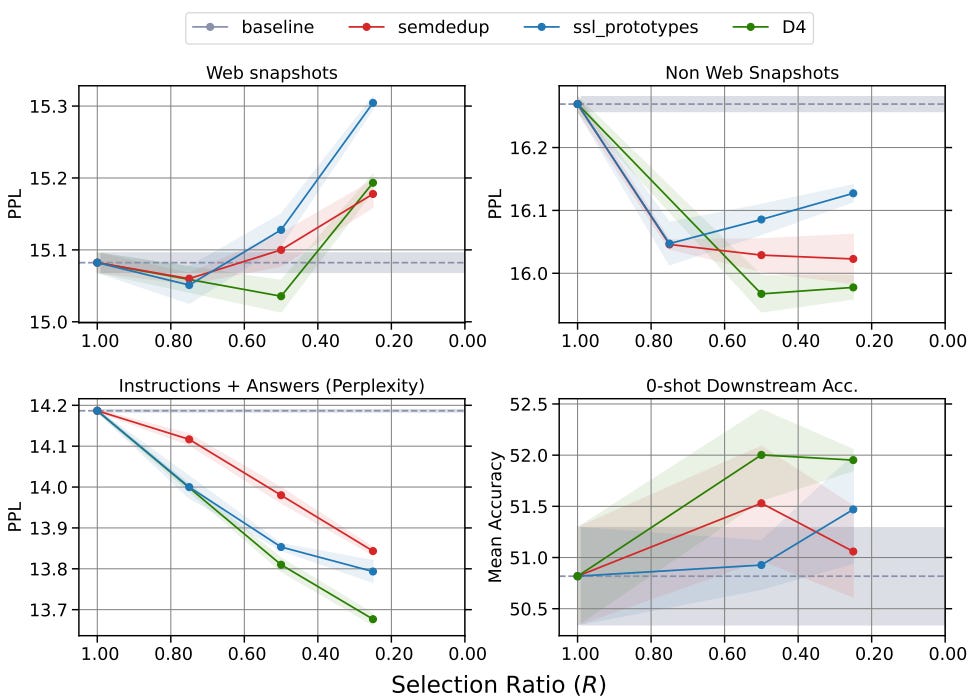
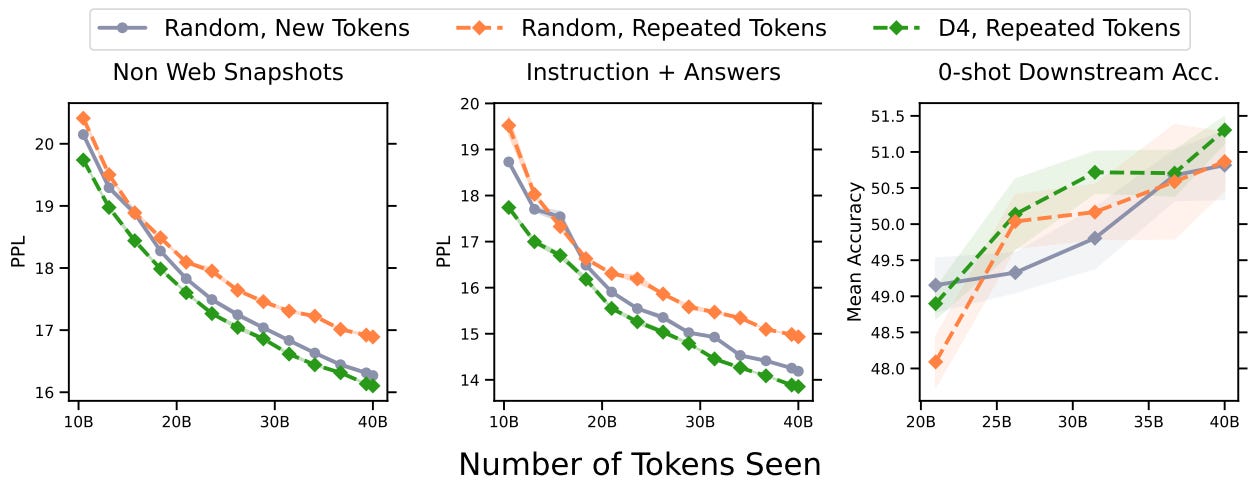
Validation was then done in the fixed-compute regime where data selection would help with fixed token budgets. As the size of the dataset grows, more data is pruned out to meet this limit. Intuitively, if the algorithm works as expected, this would mean more chance of data sample diversity/variance, and thus the model should learn more efficiently with the filtered dataset. The results are shown below and can be interpreted as more data pruned out (increased selection ratio) for an increased unfiltered dataset size using the D4 method leads to lower perplexity (lower is better).
The authors then choose to validate D4 from another perspective: the fixed data regime when new data runs out. In previous studies, it was found that epoching over the same set of tokens in multiple epochs lead to performance degradation. However, it was found that cleverly choosing tokens to repeat via D4 outperforms randomly selecting new tokens. In other words, strategically choosing a significantly smaller but better-distributed subset of the data to epoch over multiple times could provide the means to continue improving models despite the lack of new data. The results can be shown as follows:
Data Quality Control through Better CLIP Scores
What is a CLIP score? For some preliminaries, Contrastive Language-Image Pretraining (CLIP) from OpenAI is a training method for an image-text model that optimizes for representational alignment between paired image-text inputs. This creates a joint latent space where images and captions are close in this space and unrelated images and captions are further apart.
CLIP scores are calculated as follows: using a pretrained CLIP model by first passing images and text through the respective CLIP encoders to generate embeddings. The cosine similarity between these vector embeddings are the CLIP score. This score method has been widely used to quantitatively measure image-text alignment for data quality control in data pruning and is the best-performing baseline algorithm in DataComp. However, in recent years, CLIP score has been determined to have several undesirable properties and biases that will be addressed in the next several sections.
Parrot Captions Teach CLIP to Spot Text
Paper: https://arxiv.org/pdf/2312.14232.pdf

Similar to spurious correlations, CLIP score is inherently flawed because there is strong bias in the training set giving high CLIP scores to captions that are the same as the text written in the image. This biases the model to give strong Optical Character Recognition (OCR) abilities but slows down learning representations for other capabilities.
The authors propose a simple fix where they use an OCR model to extract text in an image, compare set similarity between the OCR text and caption, and prune out samples that have set similarity above a threshold. They find that by debiasing and balancing out the pretraining dataset LAION-2B in this way, performance results on many downstream tasks are then improved as the model learns stronger abilities understanding visual representations.
T-MARS: Improving Visual Representations by Circumventing Text Feature Learning
Project Page: https://tmars-clip.github.io/

Another work in parallel, T-MARS, discovered the same problem and proposed an alternative efficient solution to remove such biased CLIP scores. The bottleneck in the method from the previous section was the overreliance on the OCR model to detect and accurately write out the text from any image, which is a difficult task to make no mistakes on. To circumvent this bottleneck, T-MARS proposed to use a text detection model (instead of recognition) instead and masked out/inpainted the text region in the image with the surrounding average color. CLIP score is calculated again for the inpainted image-caption pair, and if the CLIP score suddenly drops below a threshold, then this pair is shown to be biased for OCR and is thus pruned out. This method is visually shown below:
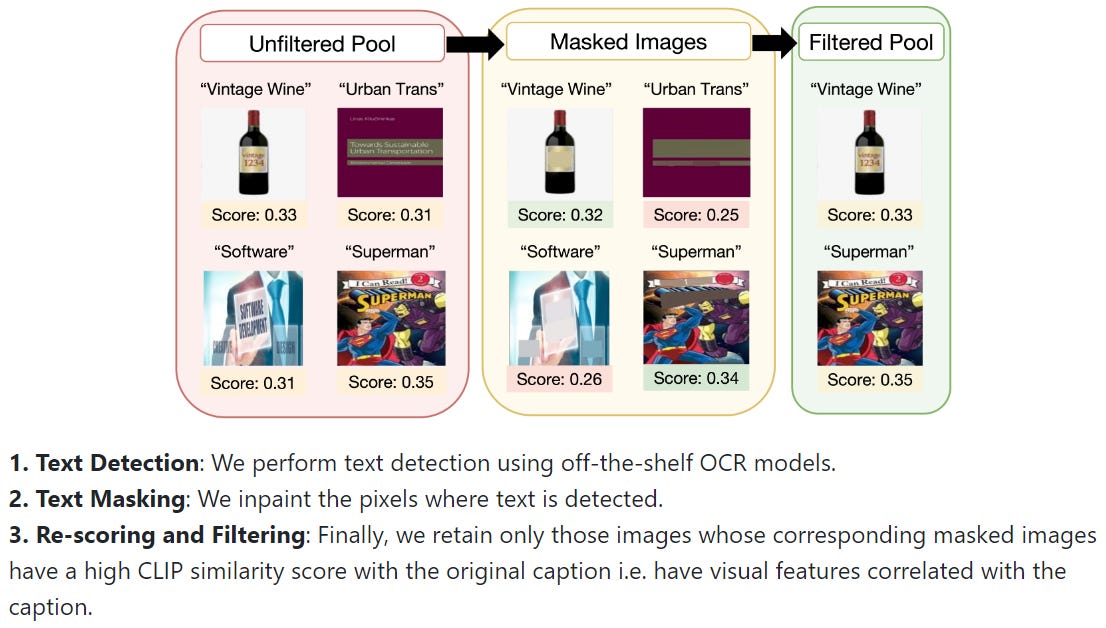
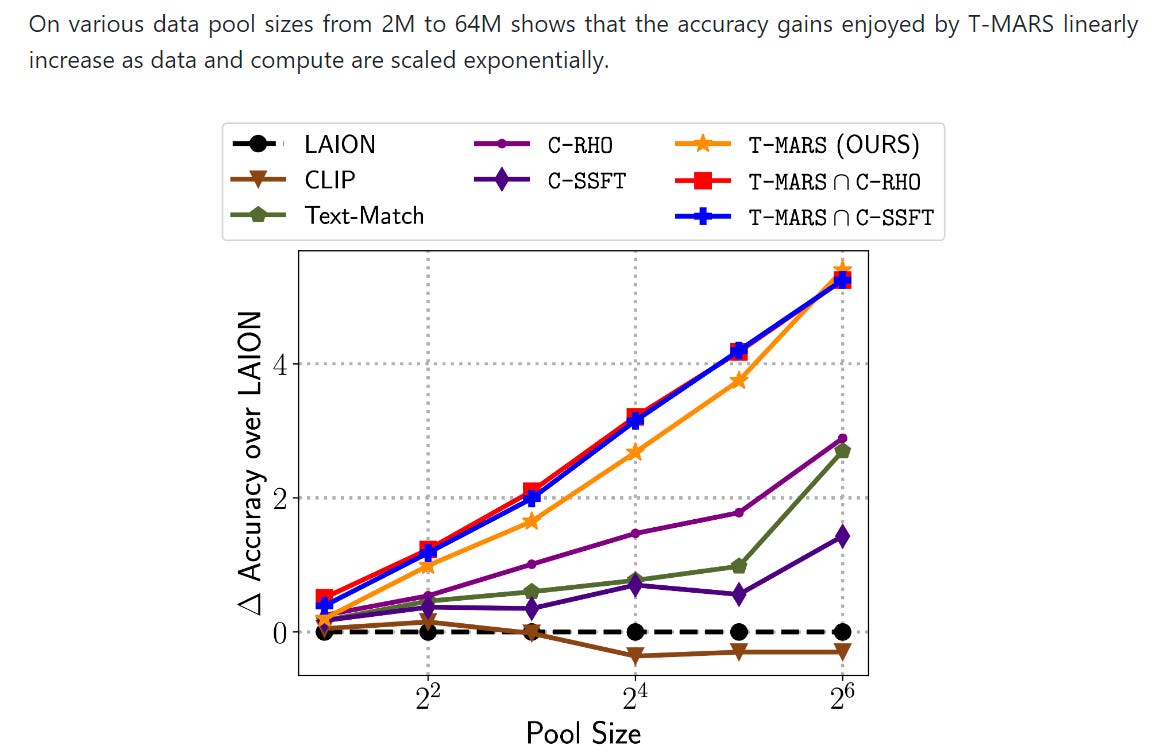
Overall, in my opinion, this method is more efficient, reliable, and scalable. The results can be seen as follows:
SIEVE: Multimodal Dataset Pruning Using Image Captioning Models
Paper: https://arxiv.org/abs/2310.02110
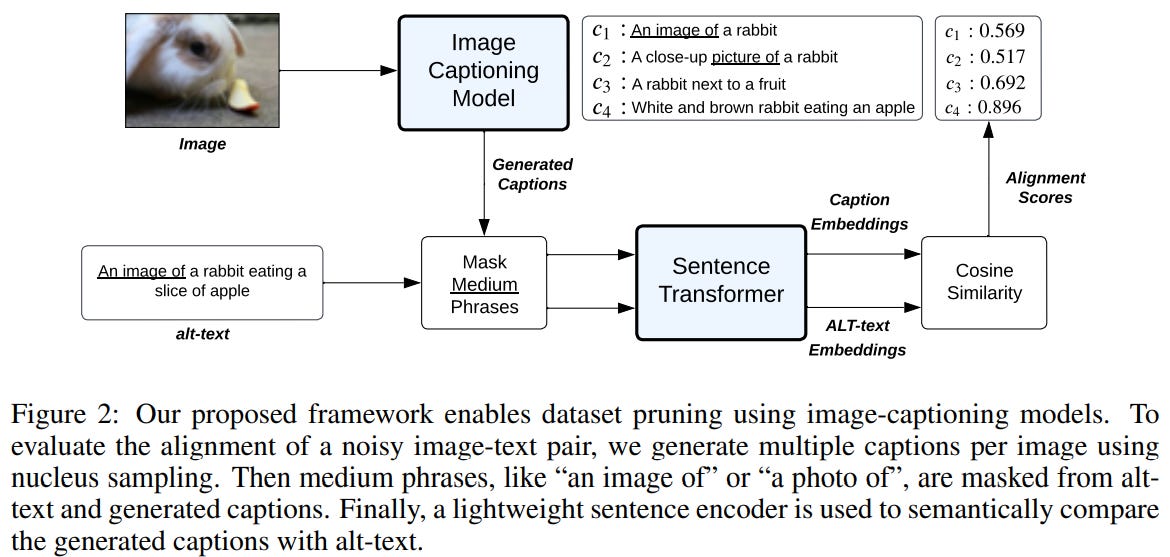
For another amazing work by Ari Morcos and friends at FAIR, they propose a more robust alternative to CLIP score.
Algorithm Outline:
Input: Image and caption (the alt-text) pair from web-scale data.
Models used: BLIP for image captioning and all-MiniLM-L6-v2 for sentence embeddings for text distribution alignment and cosine similarity calculation
Use BLIP to generate several captions (via nucleus sampling) for an input image
Mask out media words like “this is an image for” from generated text and caption
Attain sentence embeddings via MiniLM since generated text and caption come from different distributions
Calculate cosine similarity between each generated sentence embedding and caption embedding and your final score is the max cosine similarity
Optionally, take the min-max norm of both SIEVE and CLIP scores and a weighted average of the two for the final score metric
Finally, prune unfiltered dataset by selecting for samples in the top k% of scores
They find that SIEVE improves upon CLIP score and the combination of the two significantly outperforms either individually. The results are shown below for ImageNet accuracy after pretraining with the filtered data and the average DataComp downstream evaluation performance on 38 different tasks.
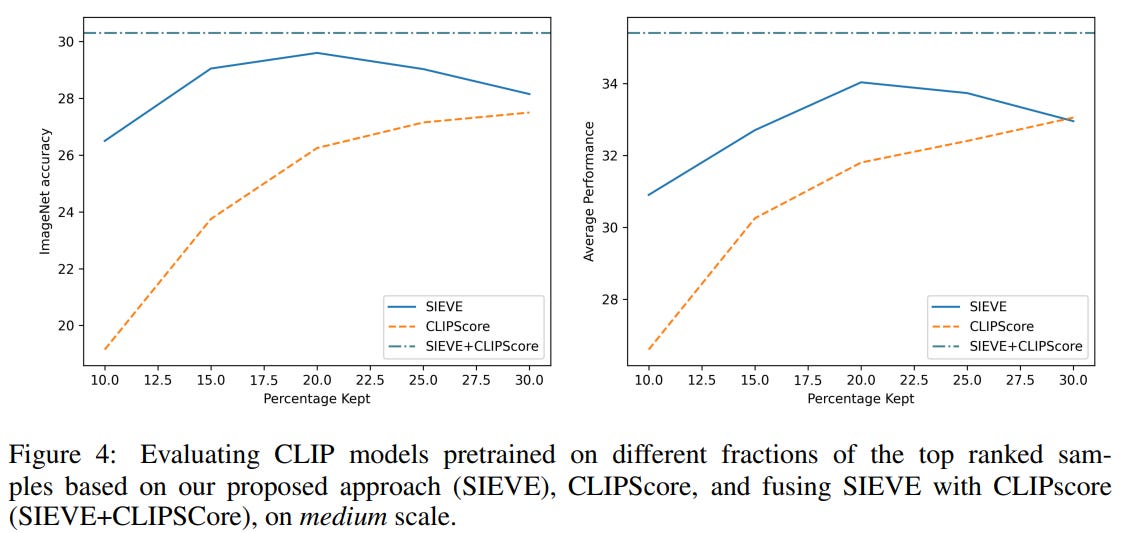
Conclusion and Future Works
Data pruning, an essential technique in the ever-growing field of Data-Centric AI, offers significant performance and cost benefits. Recently, this method has experienced a notable increase in interest, particularly in areas like alignment and data quality scoring. Data pruning algorithms, particularly those that function in embedding spaces, have shown to be scalable and efficient.
Many of these algorithms build off each other and provide some additional insight into interpreting what bad data qualifies as in unsupervised settings. What several of these embedding space pruning algorithms have in common, though, is that they depend on K-means clustering as a first step. While K-means serves as a solid initial clustering algorithm, its reliance on manually tuning the K hyperparameter for optimal clustering can be time-consuming and expensive. However, the landscape of clustering algorithms has evolved significantly since the development of K-means. Newer, more efficient algorithms offer improved clustering capabilities, underscoring the need to revisit and potentially refine this component of data pruning algorithms.
Parallel to these developments in clustering algorithms, the broader field of AI has seen remarkable scaling effects in recent years. This scaling has been empirically proven to enhance performance in many downstream tasks, sometimes even exceeding human capabilities. In the model development pipeline, each component, from data to model architecture and training objectives, requires meticulous optimization. Among these, data often remains the most overlooked and understudied aspect. However, I anticipate a shift in this trend in 2024. This year, I believe, will mark the rapid growth of synthetic data and Data-Centric AI, as large multimodal models begin to scale up significantly.
As Phillip Isola highlights, world knowledge graphs will be more complete than ever before with out-of-distribution and holes in data manifolds filled through implied synthetic mappings as models begin to interact with each other. This progress marks the dawn of Data-Centric AI, setting the stage for architecting the next generation of intelligence.