


Multimodal Dataloaders go brrrrrrr
The missing survey on streaming multimodal dataloaders for large scale training

Why should we care?
When you use search for keywords like “survey of multimodal dataloaders” on your favorite search engine (Google, Perplexity, Exa, etc), you might find research papers related to multimodal fusion or multimodal data curation, but nothing actually related to multimodal dataloaders. In the age of large-scale multimodal model training and data regime reaching petabytes of data, you’d think there would be more discussion on how to efficiently feed such data hungry models. Crucially, dataloaders directly impact training efficiency by determining experiment speed and scalability, and also ensure robustness by managing interruptions like preemptions effectively.
Despite their critical role in large-scale ML pipelines, many teams still rely heavily on WebDataset—primarily because of its popularity and ease of initial setup. Yet, it’s important to remember that WebDataset was originally designed before the widespread adoption of large-scale distributed training. As the scale and complexity of training workloads have grown, this aging format often struggles to keep up.
In practice, much of the hard-won knowledge about efficient, fault-tolerant dataloading remains siloed inside large industry labs that operate with deeply customized internal tooling. For independent researchers or smaller teams, that knowledge gap can translate into real bottlenecks. From my own experience, working with WebDataset surfaced many such pain points, especially around multi-node fault tolerance, mid-epoch restarts, and I/O consistency.
That frustration is what drove me to start exploring alternatives. If WebDataset isn’t keeping pace with modern training needs, what should we use instead? What options are actually accessible to the rest of us? And among those, which one stands out today?
To answer these questions, I compared the features and usability of four different multimodal dataloader frameworks: WebDataset, NVIDIA Megatron-Energon, MosaicML StreamingDataset (MDS), and PyTorch Lightning’s LitData. I benchmarked each framework across key tasks like data preparation efficiency, streaming performance from cloud storage, and fault tolerance. Based on these benchmarks, I’ll share recommendations on which dataloader best suits different training scenarios. And this is what I found after vibe-coding for a week straight :)) All code is released in this repository.
What’s out there?
For training with web-scale image-text corpora you need three things: a data-prep step that shards the dataset, true cloud streaming (e.g. from AWS S3 storage), and deterministic multi-node scheduling.
The obvious first question would be “why not just use native PyTorch dataloaders?” The vanilla DataLoader (even the new Stateful Iterable variant and S3 streaming) misses at least one of those boxes, which can result in slow startup, duplicated samples across GPUs, or unreliable resumptions. To keep the pipeline fast and reproducible, we benchmark four loaders that meet all three constraints: WebDataset, NVIDIA Megatron-Energon, MosaicML StreamingDataset (MDS) and PyTorch Lightning LitData. Each trades off speed, memory, and fault-tolerance differently, as the rest of this post breaks down.
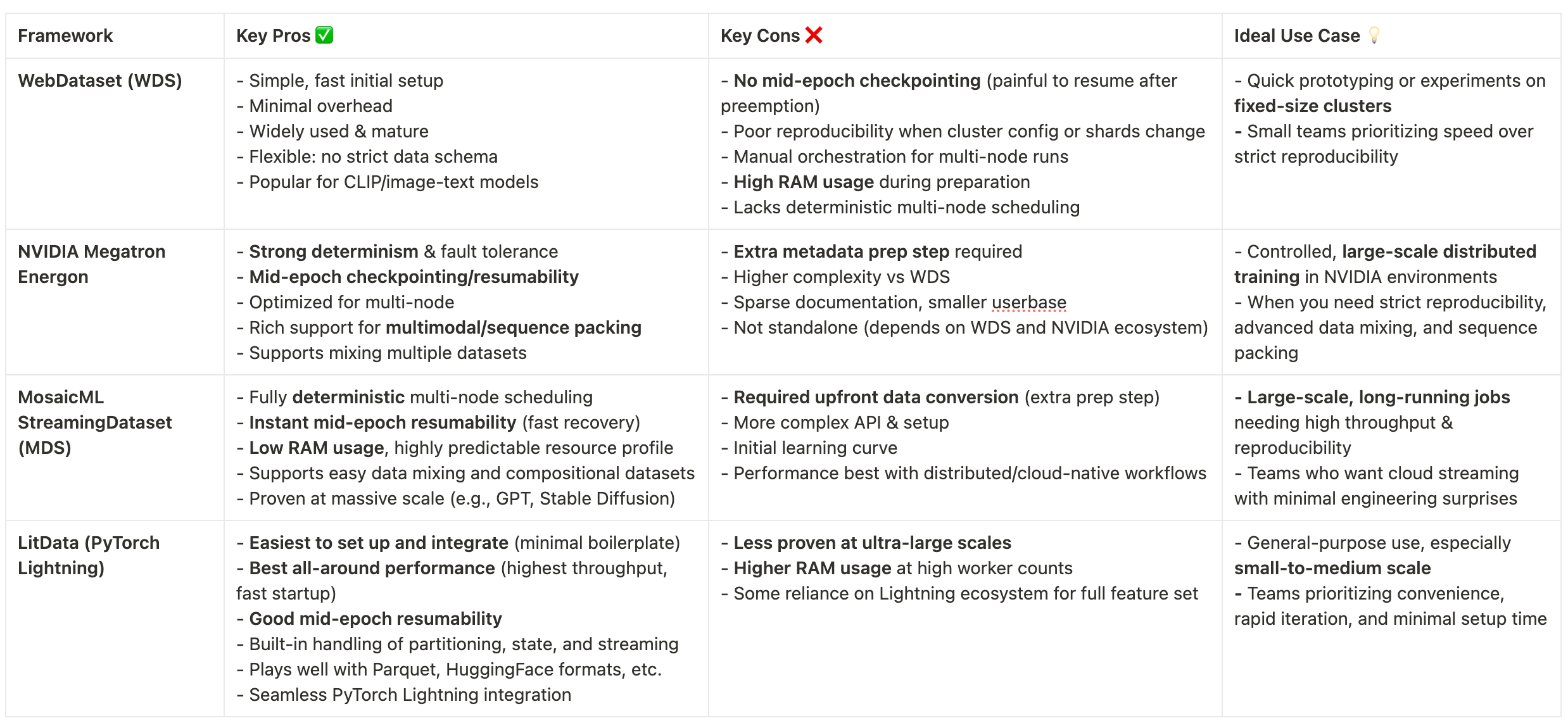
TL;DR summary of pros/cons:
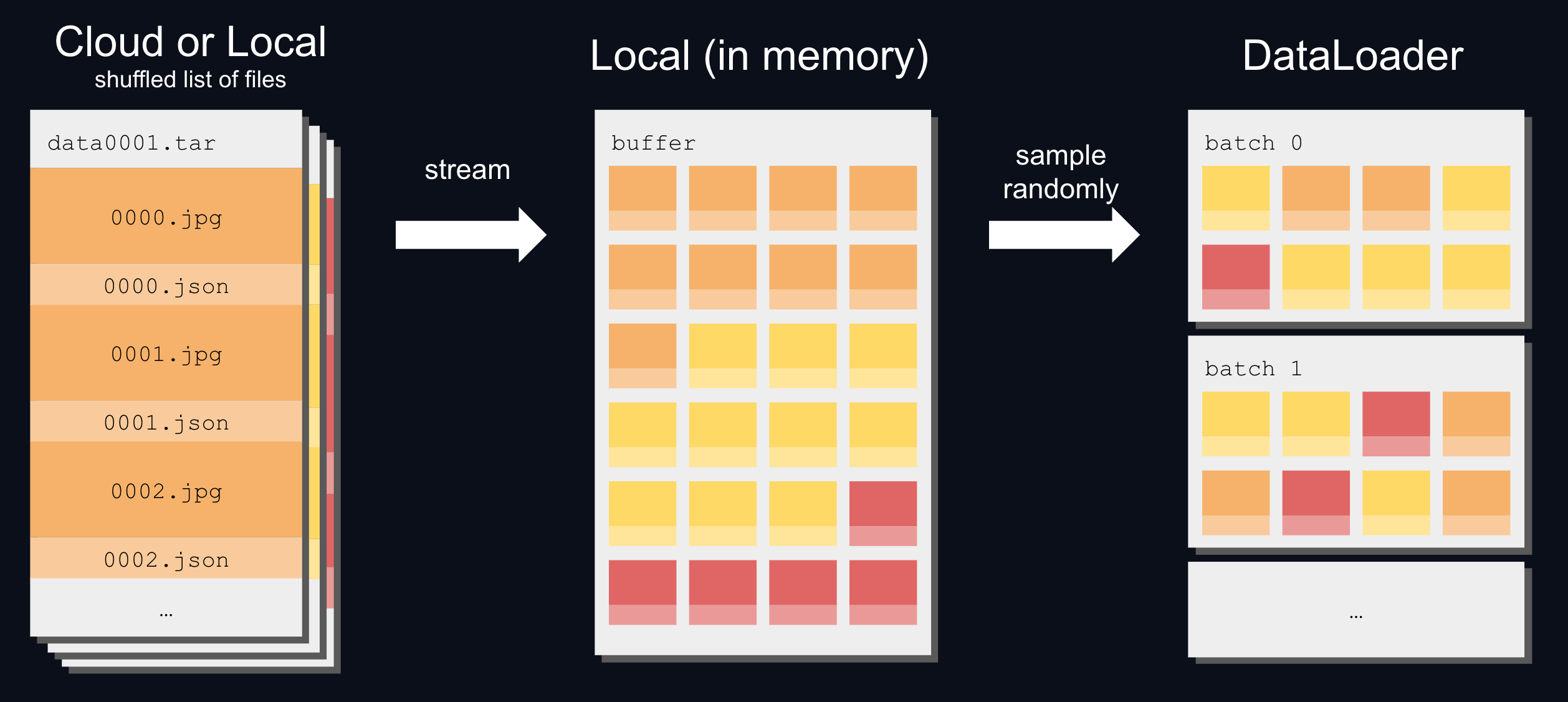
WebDataset (WDS) is one of the earliest modern multimodal dataloaders, with its first release in 2020. The data preparation stage involves packaging image and text paired samples into tarball shards. No additional metadata index is required and thus any local directory or cloud bucket of shards is immediately usable. During runtime (Fig. 1), WDS opens a streaming “pipe,” pulls the tar shards into a local cache, and drops them into a small shuffle buffer; the DataLoader then samples from that buffer to build batches.
WebDatasets were traditionally used to train image-text CLIP models, with the most popular being the OpenCLIP repository. The main draw is its simplicity as an IterableDataset with minimal overhead; it’s still being used today in major training pipelines such as SmolVLM by the HuggingFace team. With simplicity comes with much difficulty for more complex use cases. Because WDS leaves orchestration to the user, you must hand‑roll logic to make sure each of N nodes gets a unique shard subset and every shard is seen exactly once per epoch. If the shard count doesn’t divide cleanly or hardware configs change (e.g different # nodes, workers, etc.), then sample order can drift, hurting reproducibility. There’s no mid‑epoch checkpointing either, so preemptions or node failures usually mean restarting the epoch (and potentially reshuffling). One famous example of this failure mode was when Meta ran into this during OPT‑175B training: engineers had to “spin” the loader, fast‑forwarding through millions of samples to reach the correct offset, a process that burned up to 30 minutes of idle cluster time each hit.
Bottom line: WDS excels at fast setup and streaming on a fixed-size cluster, but you’ll need extra tooling for deterministic multi‑node runs or scaling up training.
NVIDIA Megatron Energon was born out of their Megatron-LM framework for large-scale training. It leverages WDS as a base, but introduces an extra metadata layer and data preparation step for better distributed training. Starting with WDS shards, the energon prepare command launches an interactive CLI that generates a special metadata folder (called .nv-meta). Notably, this metadata folder contains a dataset.yaml for describing the dataset structure and fields and a split.yaml to split train/val.
At runtime, the Energon loader uses these metadata files to ensure that the data is sharded and shuffled consistently across multiple nodes. It provides high-level APIs like get_train_dataset() that return dataset/dataloader object ready for distributed training. Energon also introduces other useful functionality such as mixing multiple datasets, performing multimodal sequence packing (Fig. 2), and mid-epoch resumability.

The main sell of this dataloader is its reliability and fault-tolerance: because of the indexing, Energon guarantees that each node/process gets its share of unique data with deterministic shuffling. Resumability is implemented through a SavableDataset where both the model and dataset are checkpointed periodically. With this additional functionality, however, comes some more complexity in managing training logic. This library is also relatively new, so documentation is more sparse and requires reading source code to use the full feature set.
The ideal use case for Energon would be for training large multimodal models in a tightly controlled distributed setting, especially if you’re already using NVIDIA’s training stack. It’s also a strong contender if you prioritize reproducibility in a multi-node setting and have already invested in defining your complex desired data format for training.
MosaicML Dataset (MDS) is a streaming dataloader designed specifically for robust and deterministic multi-node training at web-scale. Unlike simpler loaders, MDS introduces a required data-preparation stage: raw datasets are converted into compact binary "MDS shards" using MDSWriter, accompanied by an index.json file detailing shard metadata and sample indexing as seen in Fig. 3. At runtime, the loader streams shards from cloud storage (e.g., AWS S3) into a local SSD cache, maintaining a small, configurable prefetch buffer to minimize latency. More detailed information on how dataloading during training works can be found in the docs.

MDS's standout feature is its deterministic scheduling. Each sample has a fixed "canonical" position within the global dataset, ensuring consistent ordering irrespective of changes in node or GPU count. This allows the loader to gracefully handle dynamic scaling—adding or removing nodes mid-run doesn't reshuffle data. Furthermore, MDS checkpoints the exact stream position after every batch, enabling instantaneous mid-epoch resumability after preemptions or node failures without repeating or missing data.
Performance-wise, MDS approaches local-disk speeds after initial streaming and caching. Its design inherently avoids data duplication across GPUs, significantly reducing bandwidth usage and cloud storage costs. MosaicML has extensively battle-tested StreamingDataset in large-scale deployments (e.g., training Stable Diffusion and GPT models).
In summary, MDS is ideal for scenarios demanding maximum throughput, determinism, and fault tolerance at massive scale. It excels in long-running training sessions where reproducibility and cost-efficiency are critical, though its upfront data conversion step and API complexity add overhead.
Lightning AI’s LitData integrates seamlessly into PyTorch Lightning, streamlining cloud-based streaming. LitData simplifies the data preparation step through an optimize() function, repacking datasets (Parquet, CSV, Hugging Face formats) into a compact streaming-friendly form stored directly in cloud storage. At runtime, its StreamingDataLoader fetches data chunks from remote locations without requiring explicit manual sharding or sample management.
LitData emphasizes ease of use and integration—minimal additional code is required for setup, and it automatically handles partitioning across GPUs and nodes as seen in the GIF in Fig. 4. It supports stateful loading, meaning training interruptions or pauses can be resumed precisely where left off without duplicated or missed samples, ideal for training environments prone to preemption. While performant and convenient at small to medium scales, its robustness at very large-scale multi-node clusters, however, remains less proven compared to MosaicML’s solution.
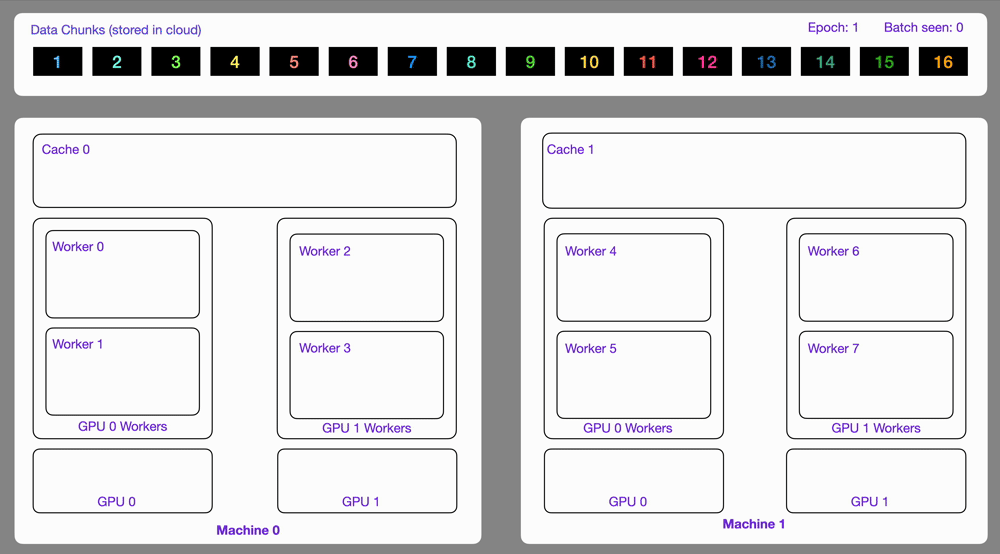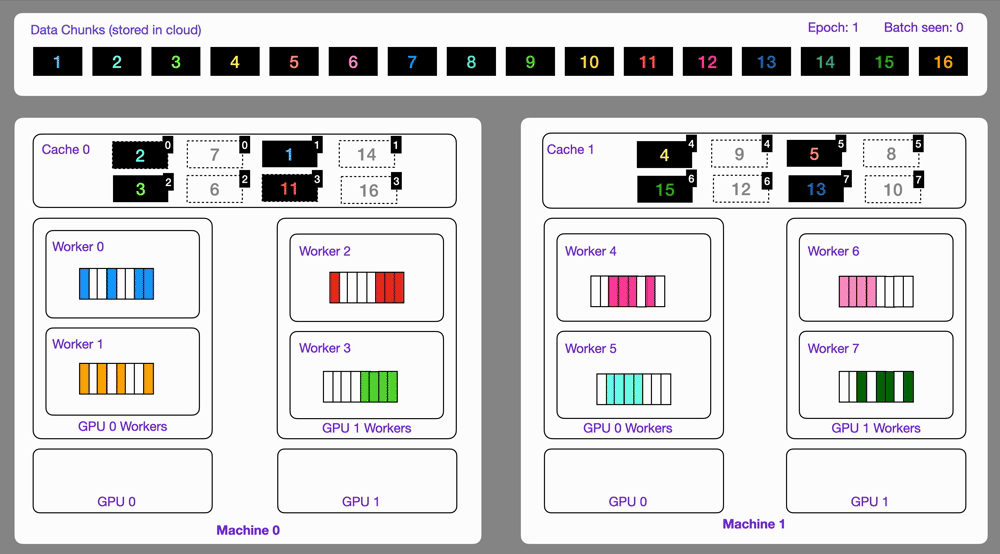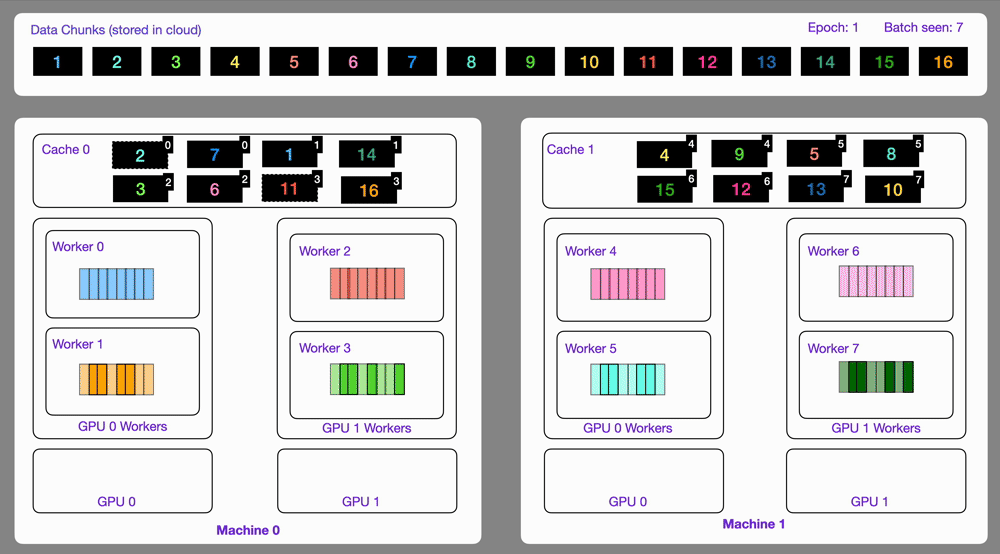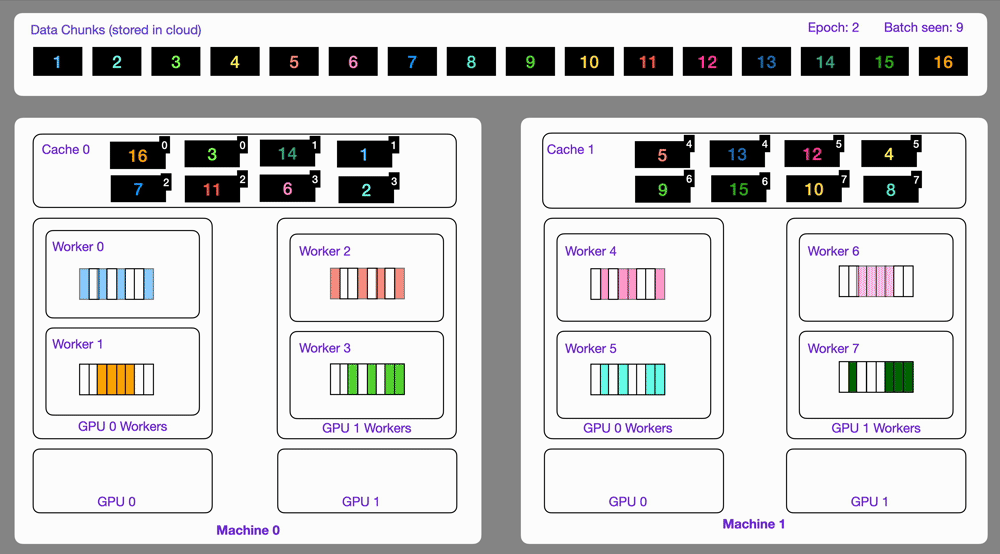
Overall, LitData is a great choice for teams who want a user-friendly streaming solution integrated with training loops, especially if using PyTorch Lightning. It hits a sweet spot in throughput vs. simplicity, giving you near state-of-the-art performance with much less engineering effort. Unless you need the ultra-fine-grained control or extreme scale handling of something like Mosaic’s solution, LitData will cover most use cases in a convenient package.
Now that we’ve surveyed the possibilities for modern multimodal dataloaders, let’s test them in a common benchmarking suite for ourselves.
Let’s Benchmark!
For all benchmarks, we used a randomly selected shard from DataComp containing 88,513 image-text pairs (~3 GB). This size was chosen as a practical upper bound for single-machine data preparation; larger datasets typically require distributed processing frameworks like Spark. This dataset is structured as a parquet file with image and text columns, containing the raw bytes of the image and corresponding caption in text characters, respectively.
All experiments were carried out on an AWS EC2 instance c5n.4xlarge equipped with a 16-core Intel Xeon Platinum 8124M CPU at 3.00 GHz, 40 GiB of RAM and a single NUMA node. The system architecture was x86_64 with KVM virtualization enabled. The operating environment was Linux kernel version 6.1.129 (Amazon Linux 2023), and Python 3.13.2 was used for all software execution.
Part 1: Data Preparation
Our benchmark pipeline implements a specialized converter for each framework that transforms the raw parquet data into the target format. WebDataset converts data to tar archives with key-value pairs, LitData prepares data using Lightning AI's optimized format, MosaicML Dataset creates streamable shards, and Energon builds on WebDataset with additional optimizations. Each converter supports multi-worker processing to evaluate scaling performance across different CPU core counts (1, 2, 4, 8, and 16 workers). Throughout the conversion process, we continuously track CPU and RAM utilization to measure resource efficiency.
We collect comprehensive metrics for data preparation, including total time (overall time taken by the conversion script, including setup and teardown), dataset write time (specific time spent writing data to the target format), size in GB (storage footprint of the converted data), number of files (total files generated by each format), and peak RAM usage in MB (maximum memory consumption during conversion). We generate comparative plots to visualize RAM usage and CPU utilization over time for each framework, providing insights into their resource consumption patterns as seen in Fig. 5. Note that energon prepare command merely builds an index over an already‑materialized WebDataset archive, so its write phase is trivial and its resource curve is dominated by bookkeeping rather than heavy serialization. Factoring this context, Energon is best viewed as a lightweight indexing accelerator rather than a full‑fidelity writer.

LitData Worker Scaling Results
| Workers | Total Time (s) | Dataset Write (s) | Peak RAM (MB) |
|---------|----------------|-------------------|----------------|
| 1 | 34.40 | 29.82 | 3439.2 |
| 2 | 24.35 | 19.80 | 6171.2 |
| 4 | 21.50 | 16.89 | 11390.6 |
| 8 | 24.08 | 19.54 | 19943.6 |
| 16 | 34.72 | 30.16 | 32913.5 |
WebDataset Worker Scaling Results
| Workers | Total Time (s) | Dataset Write (s) | Peak RAM (MB) |
|---------|----------------|-------------------|----------------|
| 1 | 22.97 | 16.66 | 6413.8 |
| 2 | 29.90 | 23.41 | 15389.6 |
| 4 | 30.19 | 23.69 | 23385.4 |
| 8 | 30.53 | 24.03 | 39262.1 |
| 16 | 31.03 | 24.51 | 73030.6 |
MosaicML Dataset Worker Scaling Results
| Workers | Total Time (s) | Dataset Write (s) | Peak RAM (MB) |
|---------|----------------|-------------------|----------------|
| 1 | 20.98 | 12.80 | 7657.3 |
| 2 | 21.08 | 12.91 | 7570.0 |
| 4 | 21.10 | 12.91 | 7513.1 |
| 8 | 21.04 | 12.90 | 7609.8 |
| 16 | 21.14 | 12.90 | 7575.9 |
Energon Worker Scaling Results
| Workers | Total Time (s) | Dataset Write (s) | Peak RAM (MB) |
|---------|----------------|-------------------|----------------|
| 1 | 23.23 | 16.66 | 4610.2 |
| 2 | 30.14 | 23.41 | 4615.1 |
| 4 | 31.46 | 23.69 | 4661.0 |
| 8 | 31.57 | 24.03 | 4731.2 |
| 16 | 31.19 | 24.51 | 4657.8 |
At a brief glimpse of the results, the main takeaway is to choose LitData (≤4 workers) when you want reliable resumability and a balanced RAM budget; choose WebDataset only when shard reuse and streaming flexibility justify extreme memory use; prefer MDS for predictable, low‑RAM jobs that are gated by disk throughput; and treat Energon as a complementary post‑processing step after completing WDS preparation.
Part 2: Data Streaming
Our streaming benchmarks evaluate how efficiently each framework loads and processes data during model training. These benchmarks stream from cloud storage (S3) to simulate real-world training scenarios. Each framework streams from its own format prepared in the preparation phase and stored in S3. For each framework, we implement a standardized data loading pipeline that streams data from S3, performs image preprocessing and resize operations, and batches samples together.
To ensure consistent performance measurement beyond initial caching effects, each benchmark runs for two epochs. We evaluate performance across varying batch sizes (128, 256, 512, 1024), worker counts (4, 8, 16), and prefetch factors (1, 2, 4) to understand how these parameters affect streaming efficiency.
We collect comprehensive streaming performance metrics, including throughput in images per second (the rate at which images are processed, using the second epoch for stable measurements), time to first batch in seconds (latency until the first batch is available, measuring initialization overhead), total samples (number of samples processed during the benchmark), wall time in seconds (total elapsed time for the benchmark), and resource usage (CPU and RAM utilization throughout the streaming process).
We generate comparative visualizations to analyze performance differences between frameworks, including throughput across different batch sizes and worker counts in Fig. 6, and time to first batch for different configurations in Fig. 7. These visualizations help identify optimal configurations for each framework and understand the tradeoffs between them.


LitData emerges as the strongest all-around choice among the loaders tested, consistently achieving the highest throughput—peaking close to 4,000 samples/sec at 16 workers—while maintaining rapid startup times of around 2 seconds to first batch. WebDataset and MosaicML MDS follow closely behind, offering respectable performance, scaling throughput roughly twofold as workers increase from 4 to 16, yet consistently trailing LitData by 5–15%. Both WebDataset and MDS have slightly higher startup latency (around 4–5 seconds), making LitData preferable for scenarios demanding quick responsiveness. Energon, meanwhile, sees significant relative improvement from scaling—tripling throughput when increasing worker counts—but ultimately remains limited, reaching only about half the throughput of LitData even at its peak.
What should you use?
I’m not an expert by any means on data infrastructure engineering - this is just the tooling I have to deal with as a Member of Technical Staff (™️) at DatologyAI to try and scale my research experiments. As my CTO says, scaling is death by a thousand cuts, so fault-tolerance and multi-node training were the highest priority for me. After playing with all these different options, I’ve found more success using the LitData repo so far (not considering the PyTorch Lightning ecosystem here). But that could change - these open-source dataloading frameworks change everyday and I’ve probably read through most relevant GitHub issues - both open and closed - to set up my current training stack.
What became clear through this process is that while WebDataset remains a common default, it no longer reflects the demands of modern distributed training. Rather than defaulting to what’s most familiar, teams should actively evaluate newer formats like MDS and LitData, which offer more robust performance at scale. This write-up only scratches the surface, but it points toward a broader need: open, comparative benchmarks that help smaller teams make informed infrastructure choices without reinventing the wheel. Studying how these loaders behave in multi-node and failure scenarios would be a good place to start.
Acknowledgements
First off, thanks to Siddharth Shah for helping with the original version of this material. Huge thank you to Ricardo Monti and Matthew Leavitt for reviewing this blog post and to DatologyAI for providing the resources to run the experiments.
If this has been useful to you, please consider citing:
@misc{yin2024multimodaldataloader,
author = {Yin, Haoli},
title = {{Multimodal Dataloaders go brrrrrrr}},
year = {2025},
howpublished = {\url{https://haoliyin.substack.com/publish/post/162224081}},
}You can explore the complete benchmark code and data preparation scripts in the GitHub repository. If you’re interested in discussing more about multimodal dataloaders, distributed training, or ML infrastructure, feel free to reach out to me on Twitter/X at @HaoliYin.